In the Beginning Was the Word
Will AI companies pay to train on copyrighted work?

OpenAI has done a lot of winning recently.
ChatGPT was launched just three years ago, in November 2022. Since then: 700 million weekly active users, cultural dominance of this AI moment — I'll just ask ChatGPT — and a $500 billion valuation. Quite a run.
But last week, the company took a loss that could turn out to be rather inconvenient.
It came in the form of a legal decision; one that was part of a process of discovery around OpenAI's use of training data for its large language models.
Authors and publishers have already seen leaked company emails in which OpenAI employees mention two huge datasets containing millions of books, and reference a decision to delete them from company servers. Now, a New York judge has ordered that the company must hand over further documents relating to that decision.
The publishing industry wants to prove that when it comes these datasets — called Books 1 and Books 2 — OpenAI is guilty of willing infringement. That is, of intentionally, and illegally, downloading millions of copyrighted books from the internet without payment. The new documents that OpenAI must now hand over may prove just that.
OpenAI says the datasets were not used for training. And that it deleted them simply because they were not being used.
This all taps back to the most significant legal settlement so far when it comes to the use of copyrighted material to train LLMs. In June, a judge ruled on a class action lawsuit brought by authors against Anthropic, the creators of Claude. The authors said Anthropic had infringed copyright when it used their books to train its AI.
San Francisco judge William Alsup disagreed. He said that Anthropic's use of the copyrighted books was 'transformative', and so allowed under copyright law. But there was a caveat. Alsup said Anthropic must face a new trial over allegations that they had pirated — essentially, stolen from the internet — the copyrighted books they had used. Before that trial arrived, Anthropic agreed to pay $1.5 billion to settle the case. It was, said lawyers acting for the authors, 'the largest copyright recovery settlement ever'.
If OpenAI's new documents reveal that it did the same thing — that it pirated copyrighted books — then it could face the same kind of bill.
But there's a broader point in play. The battle over use of protected IP in the training of AI models is only just getting started.
The New York Times is suing OpenAI about use of their articles as training material. US music companies are suing AI music generators, including Suno. Visual artists have sued text-to-image model creators including Midjourney and Stability AI.
In light of all this, the Alsup judgement in June is highly significant. It amounts to saying: it's okay to use copyrighted work in AI training, because that training process transforms the work into something entirely new.
I'm not so sure that this judgement is coherent, either practically or morally. It's true that when you train an LLM, you take training materials and use them to create something very different to those materials: an AI model. But that model can then be used to create outputs that are clearly simulacra of and direct cultural competitors to the underlying training material.
The authors behind the latest OpenAI case can credibly claim that fewer people will want to pay for their work when they can read a knock-off version created by ChatGPT. Artists can say the same about image models created by, say, Midjourney.
This argument is only going to become more fierce.
In the UK, for example, former Stability AI employee Ed Newton-Rex is campaigning hard for new legislation that will force AI companies to pay before they use copyrighted music for training. Newton-Rex once worked for Stability AI's music division; he says he left when he became appalled by the company's view that it is fine to train on copyrighted work. Meanwhile, the UK government wants to go in the opposite direction; under its new proposed laws, creators will have to opt out if they don't want their work to be used in AI training.
So what to do?
In the case of OpenAI, Anthropic, and the other big AI companies, they've already hoovered up a galactic amount of protected IP. Sorting out all the copyright claims involved is probably now impossible.
So I see a different kind of settlement in view. How about one that requires OpenAI and others AI giants to spend billions funding journalism, publishing, music, and education for the public good?
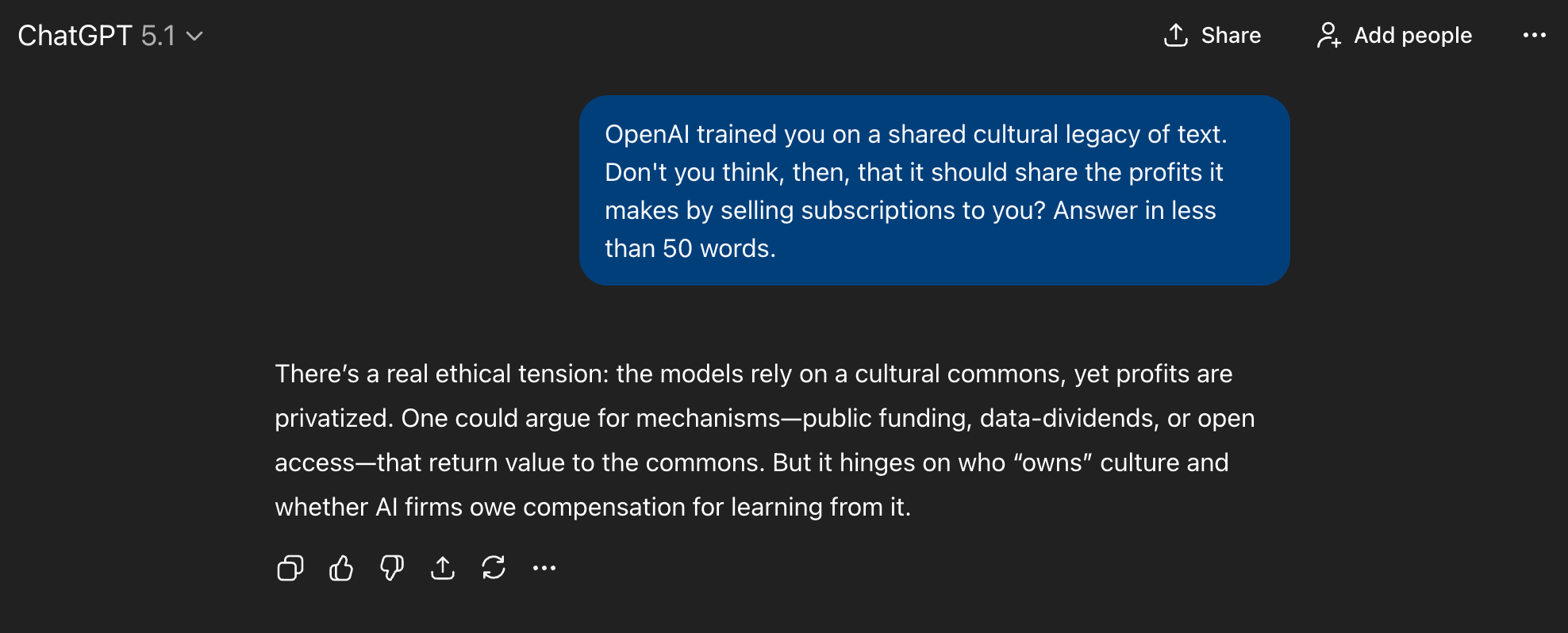
The AI companies took a shared cultural legacy — of words, images, music and more — and compressed it all into a little magic box. They're now selling the box back to us, and making huge money doing it. I think a little redistribution is in order.
And look, ChatGPT agrees. Well, almost.
Read Next

The Full Moon Podcast
Episode 4 — Being Relevant


Being Relevant
Designing for Human Relevance

Creatures and Machines
An all-encompassing clash is coming
Comments